Today's post is going to highlight some of the differences in how Power Query and the Data Model handle duplicate or distinct values, particularly when it comes to case sensitivity and messy data.
While this isn't a common issue with database source data, many of us use Excel or other less reliable data sources where this might be a potential issue. I've had a few questions around this issue, the most recent being one from @Ana2022 in the Power BI Community.
Case Sensitivity in Power Query
Consider the below table, with two distinct names:
- ACE
- Excel with Allison

These names are split across 5 rows, with some duplicates. Note they also are written with different combinations of uppercase and lowercase letters. I know that 'Excel with Allison' is the same as 'Excel with ALLISON', and ACE is the same as Ace.
IMPORTANT: We will prove in this post that if ACE is a different company to Ace, then you will need to create a unique ID that does not depend on case sensitivity.
Remove Duplicates
Let's start by doing a remove duplicates on the Name column:

Power Query returns 4 distinct values - but we know there are only 2 distinct values.
Load to Data Model
Ok, let's try loading this data to the Data Model (Close & Apply in Power BI or Close & Load to in Excel).
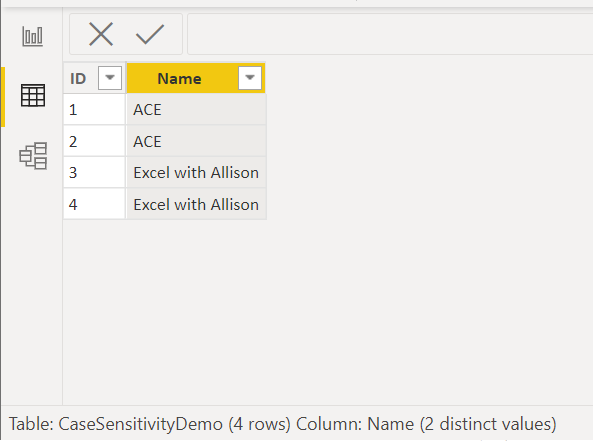
So, there is no case sensitivity in the data model. When we load data, Power BI takes the uppercase/lowercase of the first value it loads and applies that to all subsequent values.
This makes many things very difficult (among them are Sort by Columns, 1 to many relationships, and distinct counts).
To overcome this difference, we can choose a case in Power Query and apply that before removing duplicates.
UPPERCASE all values
I want ACE to be all uppercase and Excel with Allison to be proper case. I like the values that were loaded previously, so the order they're in works well. That means I don't want to transform the existing name column to all UPPERCASE, because I'll ruin the Excel with Allison.So, we'll add a new column:
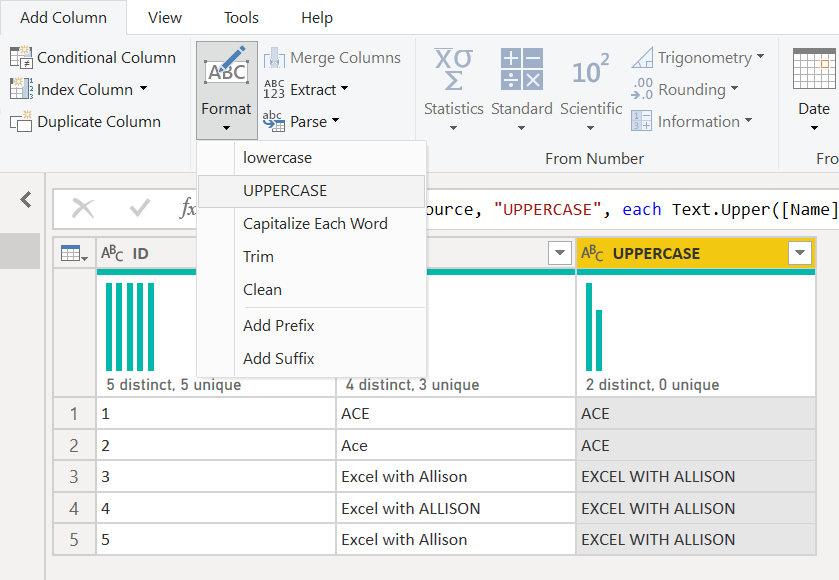
Now I will remove duplicates on the UPPERCASE column;

This leaves us with exactly 2 distinct values as we expected, and when we load these into the Data Model they will all be unique.
If we want, we can remove the UPPERCASE column, as it's not needed anymore.

Trim Text - Spaces in Power Query
Another common problem we see with Remove Duplicates occurs when there are invisible characters after the text value. Take for example this table, which appears to only have three distinct values: "Insurance", "Rent" and "Salaries" but Power Query says it has 4 distinct values:
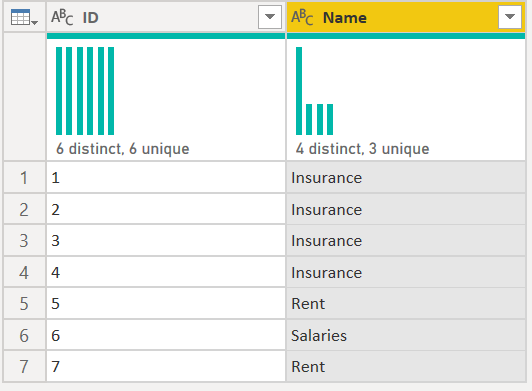

Insurance is listed twice in this bar graph, so it must have the multiple distinct values.

Here we can see that it is searching for [Name] = "Insurance" or [Name] = "Insurance " so there are spaces after Insurance in some rows.
To remove the spaces, we can use a TRIM function:

Conclusion
The Power Query functions located in the Transform > Format button in the ribbon can be vital in the process of getting a unique list of values for use in the data model.