Proper Merging Technique
Merging tables in Power Query is as challenging as it is to merge on the road, and it's just as important to get it right. If you make a mistake when merging tables, you could end up with corrupted data! In this post, we will look at why merging can cause unwanted duplication in your data and how to avoid this.

When driving, we are often told to 'Merge like a zip' - meaning for every car in the left lane, only one car from the right lane is allowed. If we replace the word 'car' with 'row' and 'lane' with 'table', we can apply this same technique to Power Query:
For every row in the left table, only one row from the right table is allowed.
While this is not always the case, it is a good technique to follow if you don't want to duplicate the data in your left table. On the road we can't copy the cars in the left lane, but in Power Query that's exactly what happens with our data - it gets copied. This duplication of data can throw off your report and cause a bigger headache than a fender bender.
Definition: Merge
A merge starts with a long data table and pulls in data from related lookup tables to create one flattened data table. You may be familiar with the VLOOKUP, HLOOKUP, INDEX or MATCH functions in Excel, merging tables can achieve the same result, but much faster and has the capability to pull in multiple fields at once.

Join Kind
A merge can also be used to filter out unwanted data (such as invoices that have already been processed or products which have not been sold). This is achieved by selecting the correct Join Kind for the merge.
Power BI offer six options for Join Type when merging tables.
Left Outer – All data from the first table, matching data from second
This is the typical result achieved through VLOOKUP in Excel. In the example of a Sales table of all sales for the month merged with a Product table containing a list of all product information, this would be a great way to pull in product name, price and cost based on the product ID in the Sales table. If a product wasn’t sold that month, it will not be pulled through into the merge. However, if there was a sale for a product not in the product list, this sale will still be pulled through into the merge, just with empty fields for product name, price, etc.
Right Outer – All data from second table, matching data from first
This is similar to the Left Outer join, but when your tables are in reverse order.
Full Outer – All rows from both
This is useful if you want to see empty data. In the Sales and Product table’s example above, this would also pull through the product information for snow boots and shovels, even if there were no sales for them in February. The columns for sales date, etc. would be empty.
Inner – Only matching rows
This is a great way to filter your data while merging with additional columns. Continuing the example from above, this could be useful for someone from the clothing department. They start with the Sales table of all sales of all products for the entire company. Then they merge with a Clothing Products table which only has the products from their department. An Inner join will result in a table with sales and product info for clothing products only if they were sold that month.
Left Anti – Rows only in first table
This is a great way to filter your data. Because it pulls through rows only in the first table, you won’t get any additional columns. In the example above we could merge the Sales table with a list of products available on the website. The Left Anti join will leave us with only the sales for products that are not available online, thereby showing us the most popular products that we might want to make available on the website.
Right Anti – Rows only in second table
This achieves similar results to the Left Anti join but with the tables in reverse order.
Improper Technique: Merge adds rows
For merge tables with a Left Outer join, the second/right table should have unique values in the column(s) you select as the matching columns.
For example:
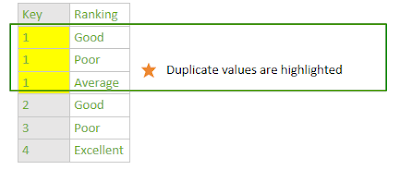
Consider the below two tables, merging them as a Left Outer Join, using the Key columns as the matching columns.

Merging with:
Desired Result:
(No added rows)
Ideally, we want to have the same number of rows that we started with - one for each country. However, what do we put for USA ranking?

There are duplicates in the Key column in the second table, so when we do a Merge, Power BI or Excel won't know which row to choose for Key 1.
Options without adding rows are:
2 (count of rankings)
Good (first ranking)
Average (last ranking)
These are all AGGREGATIONS of our data, and I do NOT recommend doing an aggregate merge as it can decrease the overall performance of your query.
So, if we do an expanded Left Outer Merge, what will our actual result be?
Actual Result:
(Added rows)
In the image below, you can see that when we expand the Ranking column from our second table, this adds two extra rows to our data!

The impact of this on your report can be as catastrophic as failing to merge like a zip on the road.
Proper Technique: Use Unique Key
To achieve the desired result, we must use a UNIQUE KEY column as the matching column for our Table 2 merge. You can use the Column distribution in Power Query to see if the first 1000 rows of your column has unique values, and the Column profile to easily identify which values are NOT unique:

Ideally, you would have a unique key in your data set. This might mean you need to combine two (or more) columns, such as:
- Country, Region
- Order Number, Order Line
- Date, Time
If you don't have a unique key in your dataset, consider WHY you are doing this merge and WHAT information you wish to report on. In some cases, you may want the duplicate rows (note this is very uncommon).
In this example, I only care to display the latest ranking, so I need to ensure my data is sorted, and then remove the duplicates only on the column (or columns) which will be used in the matching for the merge. Note there are no exact duplicates when we look at the entire table - each ranking for Key 1 is different.

We need to focus only on the Key column to remove the duplicates. Let's assume this data has come in date order, so no need to sort. So, we can remove all duplicate Key values, leaving us only with the first row of each Key:

To remove duplicates:
- Select the column or columns that will be used as the matching column(s) in the Merge.
- With the columns selected, in the Home tab > Remove Rows > Remove Duplicates.
- Note the formula bar - this operation only looks at the SELECTED COLUMNS, in this case "Key", to decide which duplicates to remove, and keeps the top row only.

Now, we can perform our merge.

And expand the Ranking column:

Our final result still has only 4 rows:

Conclusion
When doing a Merge in Power Query, we must use a Unique Key if we do NOT want to duplicate records of our data. To keep things simple, that unique key must typically be in the second/right table of the Merge for any join kind.



